gget
Efficient querying of genomic databases.
57 个版本
Python >=3.12
安装
pip install ggetpoetry add ggetpipenv install ggetconda install gget描述




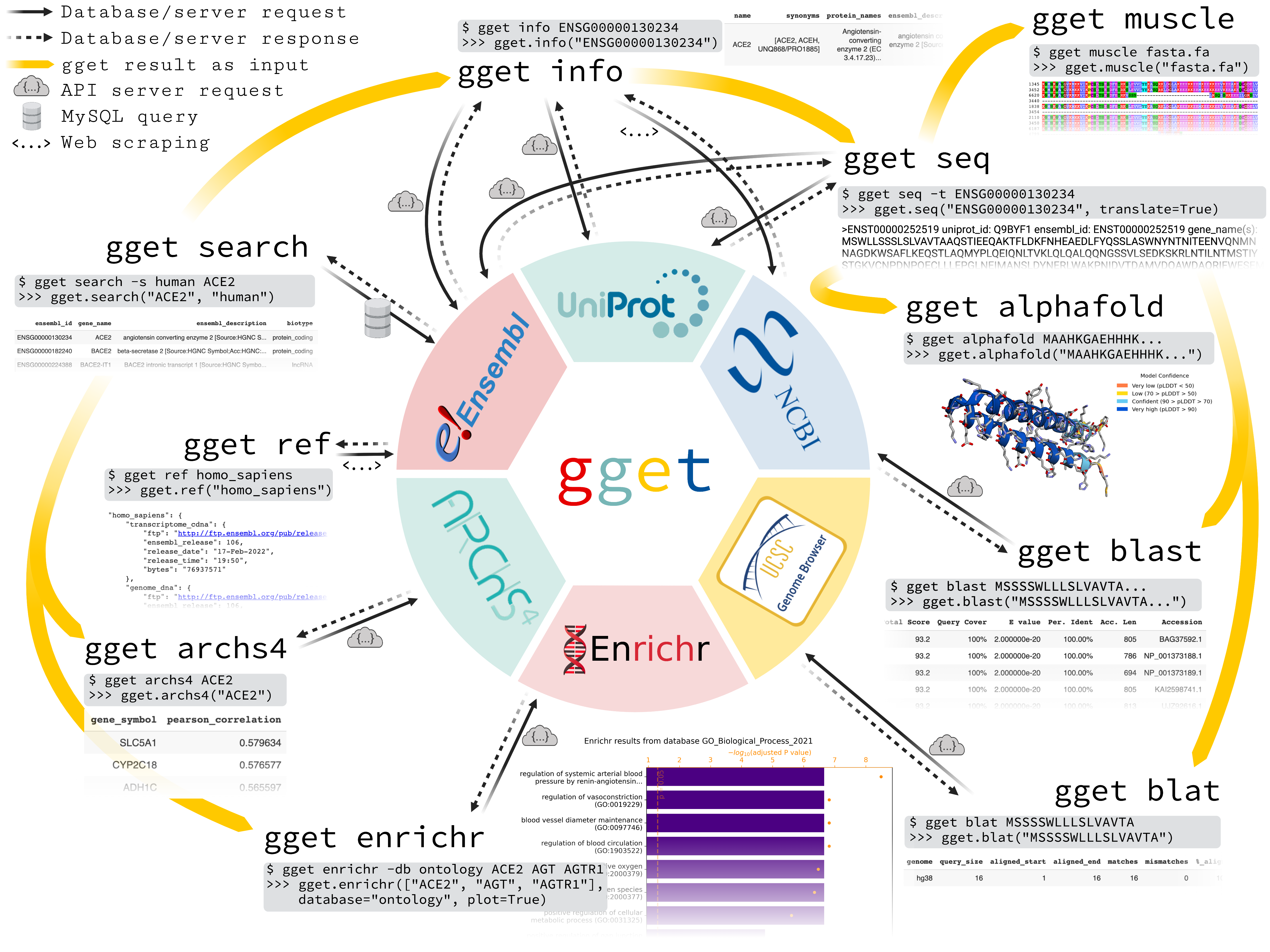
分类
Environment :: Console
Framework :: Jupyter
Intended Audience :: Science/Research
Operating System :: OS Independent
Programming Language :: Python :: 3 :: Only
Programming Language :: Python :: 3.12
Programming Language :: Python :: 3.13
Programming Language :: Python :: 3.14
Topic :: Scientific/Engineering :: Bio-Informatics
Topic :: Utilities
版本列表
0.30.7
2026-06-22
0.30.6
2026-06-11
0.30.5
2026-05-24
0.30.3
2026-02-27
0.30.2
2026-02-08
0.30.0
2026-01-20
0.29.3
2025-09-11
0.29.2
2025-07-03
0.29.1
2025-04-21
0.29.0
2024-09-26
0.28.6
2024-06-03
0.28.5
2024-05-30
0.28.4
2024-02-01
0.28.3
2024-01-22
0.28.2
2023-11-16
0.28.0
2023-11-12
0.27.9
2023-08-07
0.27.8
2023-07-12
0.27.7
2023-05-16
0.27.6
2023-05-02
0.27.5
2023-04-06
0.27.4
2023-03-19
0.27.3
2023-03-11
0.27.2
2023-01-01
0.27.1
2022-12-30
0.27.0
2022-12-10
0.3.13
2022-11-11
0.3.12
2022-11-10
0.3.11
2022-09-07
0.3.10
2022-09-02
0.3.9
2022-08-25
0.3.8
2022-08-12
0.3.7
2022-08-09
0.3.5
2022-08-06
0.3.4
2022-08-06
0.3.3
2022-08-05
0.3.1
2022-08-05
0.3.0
2022-08-04
0.2.7
2022-07-29
0.2.6
2022-07-08
0.2.5
2022-06-30
0.2.4
2022-06-29
0.2.3
2022-06-27
0.2.2
2022-06-24
0.2.1
2022-06-09
0.2.0
2022-06-08
0.1.2
2022-06-03
0.1.1
2022-05-28
0.1.0
2022-05-25
0.0.24
2022-05-17
0.0.23
2022-05-17
0.0.22
2022-05-10
0.0.17
2022-03-02
0.0.16
2022-03-02
0.0.6
2022-02-26
0.0.5
2022-02-25
0.0.4
2022-02-22